
Applied unsupervised learning with python 책을 기반으로 작성된 글입니다.
우리가 배우는 지도 학습 분야에서 특성 데이터는 제공 되지만 특성 변수가 무엇인지 설명하는 라벨은 제공되지 않는다. 대상 라벨이 구체적으로 무엇인지에 대해서는 정보를 얻을 수 없지만 비슷한 그룹을 함께 클러스터링함으로써 데이터의 구조를 얻을 수 있고 그룹 내에 어떤 유사성이 존재하는지 알아낼수 있다. 1장 2장에서 비슷한 데이터를 묶기 위해 처음으로 K- 평균을 사용하였다.
하지만 K-평균은 연산 부담이 크지 않지만 차원 수가 많은 데이터 셋이면 다룰 때 문제가 생기기도 한다. 또한 찾고자 하는 클러스터의 수가 몇개인지 모르는 상황이면 K-평균은 이상적인 해답은 아니다.
그래서 2장에서 계층적 클러스터링을 배웠다. 여기서 집적 방식과 분산 방식으로 동작 할 수 있다.
집적 방식은 상향식 접근 방식으로 동작하며, 각 데이터 지점을 자체 클러스터로 처리하고 링크 기준을 사용해 재귀적으로 그룹화 한다.
분산 방식은 하향식으로 접근하며, 모든 데이터 지점을 하나의 대규모 클래스로 처리하고 이를 반복적으로 더 작은 클러스터로 분할하는 형태로 동작한다.
>> 위 방식은 전체 데이터 분포를 완전히 이해하는 장점이 있지만 복잡도가 올라가기 때문에 잘 사용하지 않는다. 그래서 계층적 클러스터링 방식은 데이터에 사전 정보가 부족한 경우 좋은 대안이 될 수 있다. 왜냐면 덴드로그램을 사용하면 데이터 분할을 시각적으로 확인할 수 있으며 이를 통해 몇개의 클러스터로 나누는 것이 합리적인지 결정할 수 있기 때문이다.
또 다른 접근 방식은 밀집된 데이터를 다룰 때 높은 성능을 보이는다고 알려져있는 DBSCAN 이다.
1. 이웃으로서의 클러스터
1.1) 거리만 사용하는 클러스터링
- 서로 가까운 거리에 존재하는 데이터 지점일수록 유사성이 높고 멀수록 유사성이 낮다고 보는 개념을 사용한다.
- 특이한 데이터가 있는 경우 클러스터링이 별로 의미가 없다. 왜냐면 K-평균과 계층적 클러스터링 모두 남아 있는 데이터 지점이 하나도 없을 때까지 모든 데이터를 그룹에 포함시키기 때문이다.
1.2) 거리 개념과 밀도 개념을 함께 사용하는 클러스터링
- 인접 밀도의 개념을 통합함으로써 런타임에 선택한 하이퍼파라미터에 기반해 특이한 데이터를 클러스터 밖에 둘 수 있고, 인접한 데이터 지접만 동일 클러스터의 구성원으로 간주하고 멀리 떨어진 데이터 지점은 클러스터에 포함하지 않고 외부에 둘 수 있다.
2. DBSCAN 소개
2.1) DBSCAN가 클러스터링을 하는 원리
- 이웃의 반경의 크기와 클러스터로 간주되는 인접 지역에서 발견된 최소 지점의 수를 종합적으로 고려해 밀도를 평가한다.
2.2) DBSCAN가 고려해야하는 파라미터들
a. 이웃반경
a.1) 극단적으로 이웃 반경이 크다면
- 아마도 경계를 넘어가 모든 지점이 결국 하나의 큰 클러스터에 포함되게 될것이다.
a.2) 극단적으로 이웃 반경이 작다면
- 지점들이 모이지 못해 단일 지점만 포함하는 작은 클러스터만 잔뜩 생길 것이다.
b. 최소 지점의 수
- 이웃 반경의 크기를 보조하는 수단으로 볼수 있다.
b.1) 데이터의 밀도가 희박하면
- 이웃 반경 못지 않게 최소 지점의 수도 중요해진다.
b.2) 데이터의 밀도가 충분하면
- 최소 지점의 수는 별로 큰 영향을 주는 요소는 되지 않을 것이다.
>> 가장 좋은 옵션은 여전히 데이터 셋의 모양에 따라 달라진다. 그래서 하이퍼파라미터에가 너무 작지 않고 너무 크지않은 완벽한 골디락스 영역을 찾기를 원한다.
* 골디락스 : 이상적인 값
3) DBSCAN 구현
DBSCAN(eps = 0.5, min_samples = 10, metric = 'euclidean')
* eps : 이웃(주변) 반경
* min_samples : 최소 지점의 수(최소 포인트 수)
* metric : 거리 측정 방식
3.1) 속성 - 이웃 반경(eps)
- DBSCAN에서 아주 중요한 파라미터이다. 왜냐하면 너무 작으면 모든 데이터가 클러스터 되지 않은 채로 남겨지는 문제가 생기며, 너무 크면 모든 데이터가 비슷하게 하나의 클러스터로 그룹화돼 어떠한 가치도 제공하지 않기 때문이다.
- eps는 엡실론의 약자로, 이웃을 검색할 때 알고리즘이 사용하는 거리이다.
- 엡실론 값은 특정 데이터 지점을 순환 할때 인점 여부를 판단하는 반지름으로 사용된다.

// 이웃 탐색에 의해 형성된 모양은 2차원에서는 원 3차원에서는 구라는 것이다. 이는 데이터의 구조에 따라 모델의 성능이 영향을 받을 수 있음을 의미한다.
3.2) 속성 - 최소 지점 수( min_sample )
- 기능 공간에서 무작위로 놓인 소수의 지점들을 노이즈로 분류할 것인지 아니면 클러스터로 분류할것 인지를 따질 때 최소 지점의 수는 중요한 역할을 한다.
4) 활용 5: DBSCAN과 K-평균 그리고 계층적 클러스터링 비교
< 연습 문제 >
만약 당신은 상점 재고를 관리하며 많은 양의 와인을 받고 있다. 하지만 운송 중 브랜드 라벨이 병에서 떨어졌다. 다행히 공급업체가 각각의 일련 번호와 함께 각 병에 관한 화학적인 수치를 제공했다. 하지만 와인 병을 일일이 열고 그 차이를 시험할 수가 없다. 라벨이 부착되지 않은 병을 화학 물질 측정치에 따라 다시 묶을 수 있는 방법을 찾아야 한다. 주문 목록에서 3가지 유형의 와인을 주문했고, 와인 유형을 다시 그룹화하기 위해 2가지 와인 속성만(X_feature) 제공 받았다고 하자
//필요한 모듈 임포트
from sklearn.cluster import KMeans, AgglomerativeClustering, DBSCAN
from sklearn.metrics import silhouette_score
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
// 와인 데이터 셋 로드
wine_df = pd.read_csv("wine_data.csv")
//시각화
plt.scatter(wine_df.values[:,0], wine_df.values[:,1])
plt.title("Wine Dataset")
plt.xlabel("OD Reading")
plt.ylabel("Proline")
plt.show()

// K-평균 클러스터링
km = KMeans(3)
km_clusters = km.fit_predict(wine_df)
// 응집 계층적 클러스터링
ac = AgglomerativeClustering(3, linkage='average')
ac_clusters = ac.fit_predict(wine_df)
// DBSCAN 클러스터링
db_param_options = [[20,5],[25,5],[30,5],[25,7],[35,7],[35,3]] // 최적의 실루엣 점수 파라미터 찾기
for ep,min_sample in db_param_options:
# Generate clusters using DBSCAN
db = DBSCAN(eps=ep, min_samples = min_sample)
db_clusters = db.fit_predict(wine_df)
print("Eps: ", ep, "Min Samples: ", min_sample)
print("DBSCAN Clustering: ", silhouette_score(wine_df, db_clusters))

// 가장 좋은 파라미터를 가진 DBSCAN으로 클러스터링
db = DBSCAN(eps=35, min_samples = 3)
db_clusters = db.fit_predict(wine_df)
// 모든 클러스터링 시각화
plt.title("Wine Clusters from K-Means")
plt.scatter(wine_df['OD_read'], wine_df['Proline'], c=km_clusters,s=50, cmap='tab20b')
plt.show()

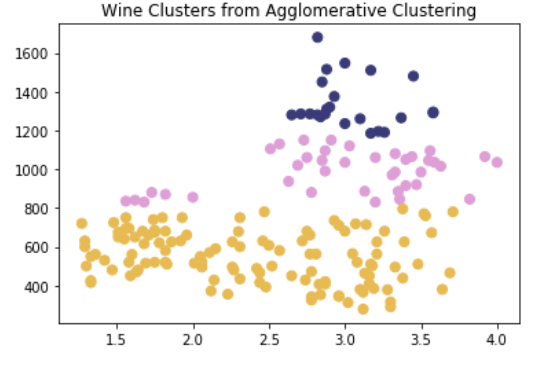
plt.title("Wine Clusters from Agglomerative Clustering")
plt.scatter(wine_df['OD_read'], wine_df['Proline'], c=ac_clusters,s=50, cmap='tab20b')
plt.show()
plt.title("Wine Clusters from DBSCAN")
plt.scatter(wine_df['OD_read'], wine_df['Proline'], c=db_clusters,s=50, cmap='tab20b')
plt.show()

// 각각의 클러스터의 실루엣 점수
print("Silhouette Scores for Wine Dataset:\n")
print("K-Means Clustering: ", silhouette_score(wine_df, km_clusters))
print("Agg Clustering: ", silhouette_score(wine_df, ac_clusters))
print("DBSCAN Clustering: ", silhouette_score(wine_df, db_clusters))

// 보면 DBSCAN이 항상 최고의 선택이 될 수 없다. 하지만 다른 알고리즘과 구별되는 특징은 노이즈를 잠재적 클러스터링으로 사용한다는 사실이다. 어떤 경우에는 특이한 지점을 제거하기에 훌륭하지만 때로는 많은 지점을 노이즈로 분류하는 문제를 만들기도 한다. 그럼 하이퍼파라미터 튜닝을 통해 실루엣 점수를 높일 수 있을까?
'비지도 학습 (Unsupervised Learning) > Applied Unsupervised Learning with Pytho' 카테고리의 다른 글
| 장바구니 분석( Apriori 알고리즘 ) (0) | 2020.02.05 |
|---|---|
| 7장 토픽 모델링(LDA) (0) | 2020.01.11 |
| 4장 차원 축소와 PCA (0) | 2020.01.06 |
| 2장 계층적 클러스터링(Hierarchical Clustering) (0) | 2019.12.28 |